在與數(shù)據(jù)倉庫、數(shù)據(jù)湖或數(shù)據(jù)庫間數(shù)據(jù)傳輸?shù)膱鼍爸校隽客绞且环N高效且資源友好的方式,尤其在處理大規(guī)模數(shù)據(jù)時。當只需同步單張表的新增或變更數(shù)據(jù)時,Ckettle提供了靈活的配置選項來實現(xiàn)這一目標。
一、什么是單表增量同步?
單表增量同步指的是僅同步目標表中發(fā)生變化的數(shù)據(jù)(如新增、更新或刪除記錄),而不是每次都全量覆蓋。這種方法能夠顯著減少數(shù)據(jù)傳輸量、降低系統(tǒng)負載并提高同步效率。
二、Ckettle簡介
Ckettle是一款開源的ETL(Extract, Transform, Load)工具,基于Java開發(fā),支持多種數(shù)據(jù)源和目標,包括關(guān)系型數(shù)據(jù)庫(如MySQL、Oracle)、文件系統(tǒng)(如CSV、Excel)和大數(shù)據(jù)平臺(如Hadoop、Hive)。其圖形化界面使得配置數(shù)據(jù)流程變得簡單直觀。
三、實現(xiàn)單表增量同步的關(guān)鍵步驟
在使用Ckettle進行單表增量同步時,通常可以按照以下步驟操作:
- 識別增量數(shù)據(jù):
- 利用時間戳字段:如果表中包含最后修改時間(如
update<em>time或create</em>time),可以基于該字段篩選出上次同步后的新記錄。
- 使用自增ID:若表中存在自增主鍵,可通過記錄上次同步的最大ID值,僅同步ID大于該值的記錄。
- 啟用數(shù)據(jù)庫日志(如MySQL的binlog):通過解析日志捕獲變更,適用于高實時性場景。
- 配置Ckettle作業(yè):
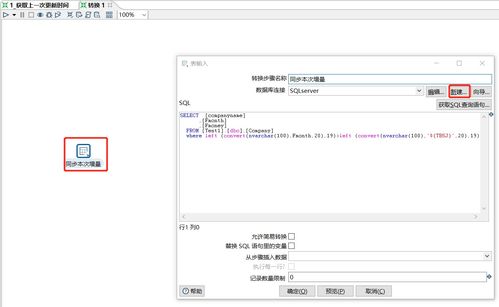
- 輸入步驟:選擇適當?shù)臄?shù)據(jù)輸入組件(如“表輸入”),并編寫SQL查詢以提取增量數(shù)據(jù)。例如:
SELECT * FROM your<em>table WHERE update</em>time > '上次同步時間'。
- 轉(zhuǎn)換步驟:根據(jù)需要清洗或轉(zhuǎn)換數(shù)據(jù),例如過濾無效值、格式化字段。
- 輸出步驟:使用“插入/更新”或“表輸出”組件將數(shù)據(jù)寫入目標表,并配置去重或更新邏輯。
- 調(diào)度與自動化:
- 利用Ckettle的作業(yè)調(diào)度功能(如結(jié)合cron或內(nèi)置定時器),定期執(zhí)行同步任務(wù),確保數(shù)據(jù)及時更新。
- 記錄同步狀態(tài)(如最后同步時間或ID),以便下次任務(wù)從中斷點繼續(xù)。
四、實踐示例:基于時間戳的同步
假設(shè)我們需將MySQL中的orders表增量同步到數(shù)據(jù)倉庫,步驟如下:
- 在
orders表中,last_modified字段記錄每條訂單的最后更新時間。 - 在Ckettle中創(chuàng)建轉(zhuǎn)換:
- 使用“表輸入”組件,SQL查詢?yōu)椋?code>SELECT * FROM orders WHERE last_modified > ?,并通過參數(shù)傳入上次同步時間。
- 添加“插入/更新”組件,配置目標表結(jié)構(gòu),并設(shè)置
order_id為關(guān)鍵字段,實現(xiàn)更新或插入。
- 創(chuàng)建作業(yè),添加該轉(zhuǎn)換,并設(shè)置每天凌晨1點自動運行。
五、注意事項
- 數(shù)據(jù)一致性:在高并發(fā)環(huán)境中,需確保同步過程中源表數(shù)據(jù)不被修改,或采用事務(wù)隔離機制。
- 錯誤處理:配置日志記錄和異常通知,便于及時排查同步失敗問題。
- 性能優(yōu)化:對大數(shù)據(jù)量表,可在源表上為時間戳或ID字段添加索引,提升查詢效率。
六、總結(jié)
Ckettle為單表增量同步提供了強大而靈活的支持,通過合理配置,可以高效、可靠地實現(xiàn)數(shù)據(jù)流動。在實際應(yīng)用中,結(jié)合具體業(yè)務(wù)需求選擇增量策略,并注重監(jiān)控與優(yōu)化,將大大提升數(shù)據(jù)管理的整體效能。